知识库
知识库是用来管理你的 私有数据的容器,上传文件到知识库中, LinkAI将会自动解析和加工你的文档,生成最适合模型"学习"的格式。
知识库需要和应用绑定才能发挥作用,二者关联后可以根据上传的文本数据提供定制化的智能问答服务,在一定程度上可以解决通用大模型 缺乏领域数据支撑、偶尔"胡言乱语" 的短板。基于知识库,你可以很轻松地上传产品使用手册和FAQs来打造智能客服、可以与通过与文档对话来学习某一知识、甚至可以上传一本小说塑造一个人物角色。
知识库管理
进入 知识库页面 点击 "创建知识库",输入名称和描述即可创建一个新的知识库:

点击知识库进入,选择 "配置" 页面,可以修改基础信息,以及删除知识库:

文件导入
创建完成后就可以上传文件了,有两种文件类型可以上传:
- 无结构文档: 无需进行任何预处理的原始文档,LinkAI会帮你进行文档拆分和加工,支持 pdf、docx、md、txt 格式的文件
- QA问答文档: 一问一答形式的语料,需要按照模板 进行预处理,支持 csv 格式
无结构文档 和 QA问答格式 怎么选择?
取决于你的应用场景,无结构文档无需语料预处理、自动导入更方便,而QA问答格式的回答准确性会更好,在有条件的情况下可以优先考虑QA类型的文档。
同时可以将二者结合来获得更好的效果,例如在客服场景可以将 FAQs 整理为 csv问答对 格式上传,让高频问题的回答质量更高;同时将产品说明、使用指引等以无结构形式自动导入,以覆盖长尾问题,降低无结果率。
无结构文档
这里我先导入一个 LinkAI个人助手的 pdf格式 介绍文档:
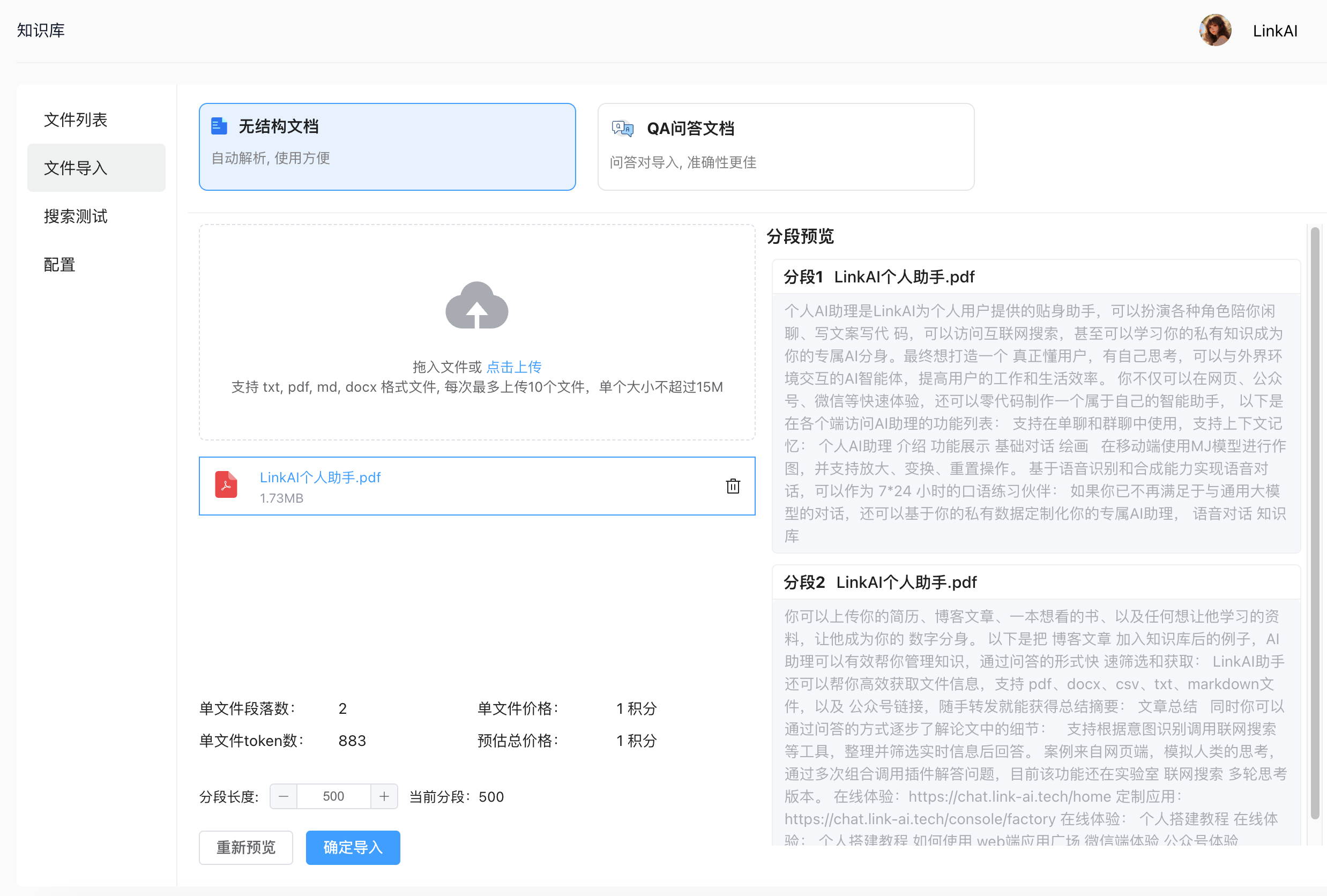
无结构文档导入后,系统会自动结合 分段长度 和 标点符合 将长文本拆分成多个段落,方便进行检索,在右侧可以看到拆分效果的预览。在左下方可以看到文件的token数量以及预估的积分价格。
另外可以设置拆分的 分段长度,注意分段长度不要设置的太大,因为机器人每次回复时将会取若干个段落放在上下文中请求模型,段落内容太长或段落的数量太长则可能超出模型上下文限制。
QA问答文档
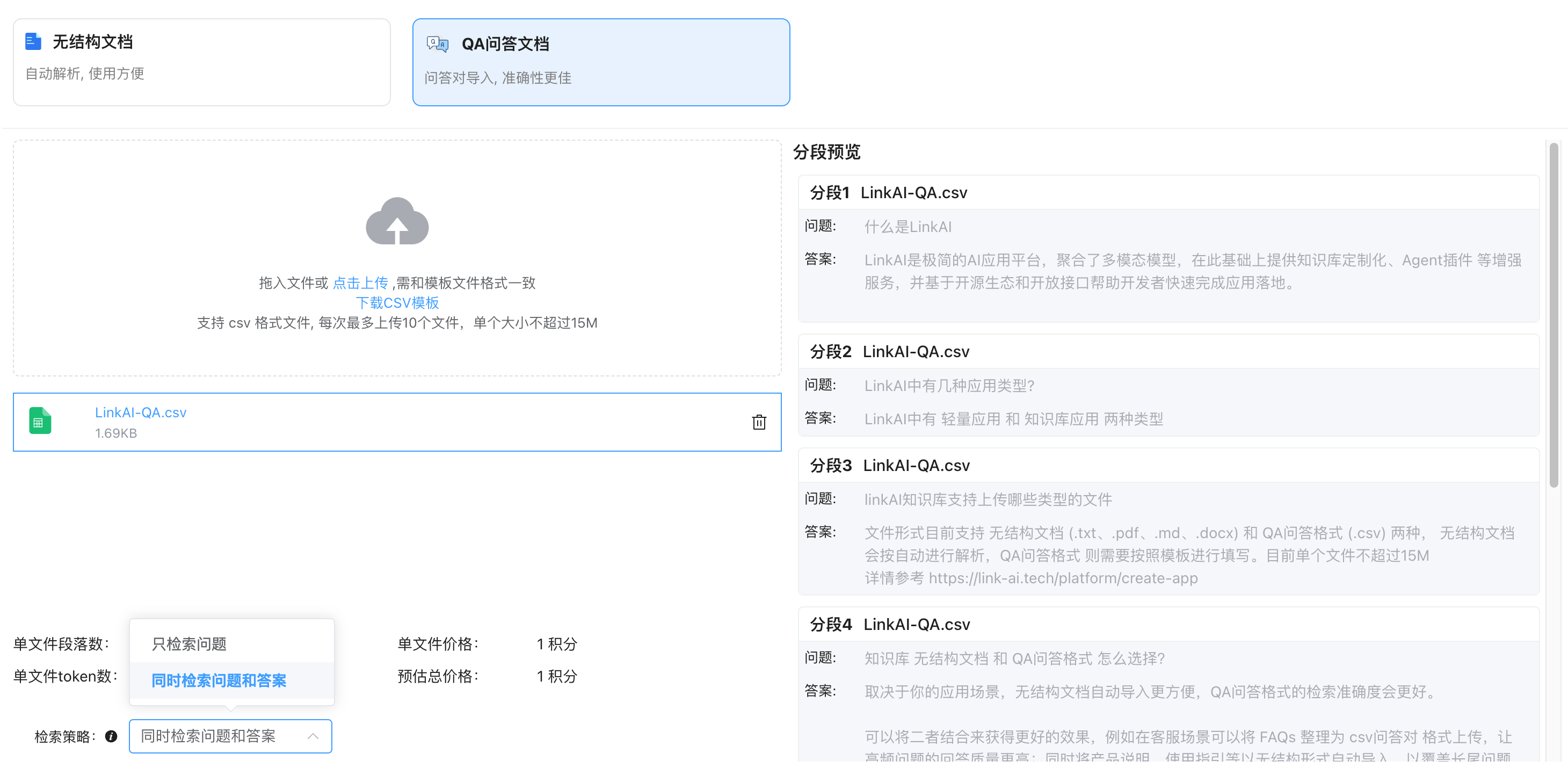
QA文档需要下载 CSV文件模板 并按格式填写,每一行有 question 和 answer两列。与无结构文档不同的是,QA类型文档在导入时可以选择检索策略:
- 默认为 "同时检索问题和答案": 即检索时会同时匹配语料的问题和答案,检索范围广但相似度较低
- 可选择 "只检索问题": 只能根据问题中的相关文本找到这条语料,但检索的相似度更高
假设有一条QA语料录入, 问题: LinkAI有哪些应用类型 答案: 轻量和知识库
此时若选择 "同时检索问题和答案" 的策略
- 当提问 "LinkAI有哪些应用类型": 检索相似度可能为0.9,可以找到这条语料并回复;
- 当提问 "什么是轻量应用",检索相似度可能为 0.85,同样可以找到这条语料并回复
此时若选择 "只检索问题" 的策略
- 如果用户提问 "LinkAI有哪些应用类型",那么相似度为1,可以精准找到这条语料并回复
- 但如果问题是 "什么是轻量应用",检索相似度可能只有 0.7,有可能就无法命中语料并回复了
所以,如果你的场景更多是根据问题去找答案,而不需要根据答案中的内容反向找到这条语料,选择 "只检索问题" 的策略会更精准,反之亦然。
数据变更
导入成功之后可以在 "文件列表" 中看到生效的文件,点击 "查看" 可以查看文件具体内容:
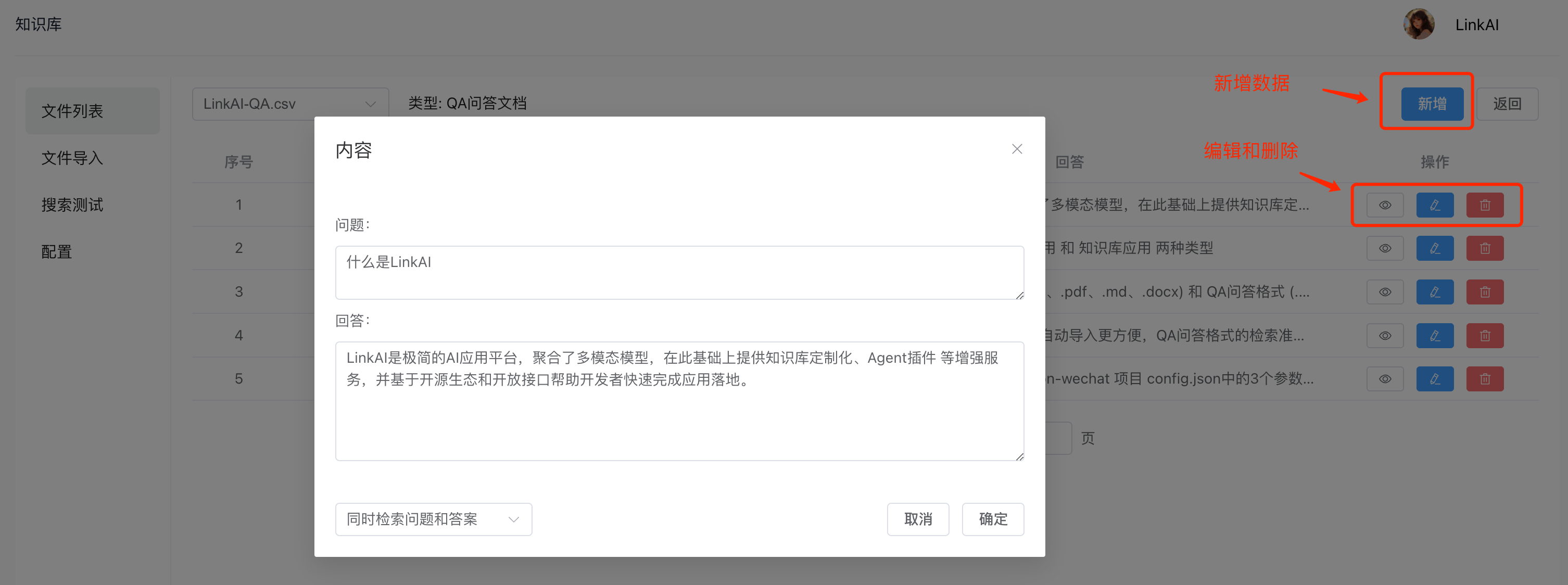
同时可以在文件中对数据进行 新增、编辑和删除。注意数据变更操作是异步进行,可能操作后页面上不会立即发生变化,最多会在几秒钟内完成同步。
搜索测试
在搜索测试页面,可以模拟用户问题在知识库中的检索过程,每条语料会展示出相似度指标,表示这条语料与问题的相关性。这个搜索测试功能将在下一步绑定应用时发挥作用。

应用配置绑定
知识库中需要在 应用配置 中进行绑定才能发挥作用,应用和知识库之间是多对多关系,一个应用可以绑定多个知识库:

点击编辑按钮可以修改知识库的策略:

配置项说明:
- 相似度: 只有在这个相似度以上的语料才会在对话中被使用,高相似度时 (如0.8以上),只会检索出与问题相关性高的知识,会更准确,同时也容易未命中;低相似度时 (如0.7以下),可能会检索出相关性低的内容,但检索范围更大。 具体设置需要根据语料情况来判断,结合上一步的 搜索测试 功能,模拟用户提问,根据各语料的相似度 选择合适的相似度配置
- 单次检索条数: 单次问答从知识库中检索的最大段落数量,默认为3条,注意这个值不能设置的过大,否则可能超出模型上下文的限制
- 未命中策略: 当没有找到知识库中内容时的策略,可以选择 自由发挥 (由机器人自行推理并回复) 和 固定文案 (根据一段指定的文本进行回复)
举个例子,假设 相似度阈值 设置为0.8,单次检索条数 设置为 3,用户提问时,最终会从知识库中检索出来的内容为 相似度在0.8以上的3条语料。
对于无结构文档,每条语料的长度是我们导入时设置的,默认为500字符,对于QA结构文档,语料的长度是 问题+答案 之和,所以这样可以大致估计出每次提问时携带的知识库内容长度了,这个长度不能超过模型的最大上下文长度。